Migrating Mainframe Data to Non-Relational Database on AWS
Question
I need to migrate millions of customers' financial transaction data from the On-Premise Mainframe system to a non-relational database in AWS.
The database should also provide good performance for data retrieval and data analytics.
Which of the following Database services is the most suitable?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Answer: D.
Diagrams:
On reading the scenario carefully, we notice that the Customer's Financial transaction data is huge.
It needs storage on the cloud.
NoSQL databases like DynamoDB are designed to provide seamless scalability by automatically partitioning the database as it grows in size.
So a NoSQL database like DynamoDB will be the most appropriate database service that can be used for the scenario.
Option A is incorrect.
Here we are exclusively talking about Huge data volumes, Data retrieval and Data analytics.
RDS databases are most useful for heavy transaction processing systems.
They also do not exhibit automatic partitioning capabilities with increased data volume & stream processing capabilities like a NoSQL database like DynamoDB provides.
Option B is incorrect.
Amazon RedShift is a Data Warehousing solution primarily used for Operational analytics on business events.
Data Warehouse may comprise a big collection of an Enterprise's structured & semi-structured data that can be used to build powerful reports & dashboards using Business Intelligence tools.
Since we only have the Customer's transactional data for our scenario, RedShift will not be a good fit here.
Option C is incorrect.
We are talking about the scenario for a data migration of On-Premise Mainframe data, which will require a permanent, secure data store for storing the highly sensitive Customer's financial data.
Caching solutions are typically in-memory data stores used for supporting applications requiring sub-milliseconds response times.
Caching solutions usually maintain a subset of the data present in a data store that does not change frequently.
Also, caching solutions do not provide any facility for performing real-time data analytics, although they provide the best performance compared to any other data storage solutions.
Option D is CORRECT.
DynamoDB provides DynamoDB Accelerator (DAX) which is a fully managed, highly available in-memory cache.
This will help us speed up the performance of data retrieval that we require.
DynamoDB also has a feature called DynamoDB streams that enables real-time capture of data changes using event notifications.
This helps applications to perform analytics on real-time streaming data to build dashboards without impacting database performance.
The stream events are asynchronous in nature to consuming applications like a Lambda function.
Since the Customer's transactional data is highly confidential & huge in volume, a robust, scalable, secure, performant data store like DynamoDB will be the best fit for our scenario.
References:
https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/HowItWorks.Partitions.html https://docs.aws.amazon.com/amazondynamodb/latest/developerguide/Streams.html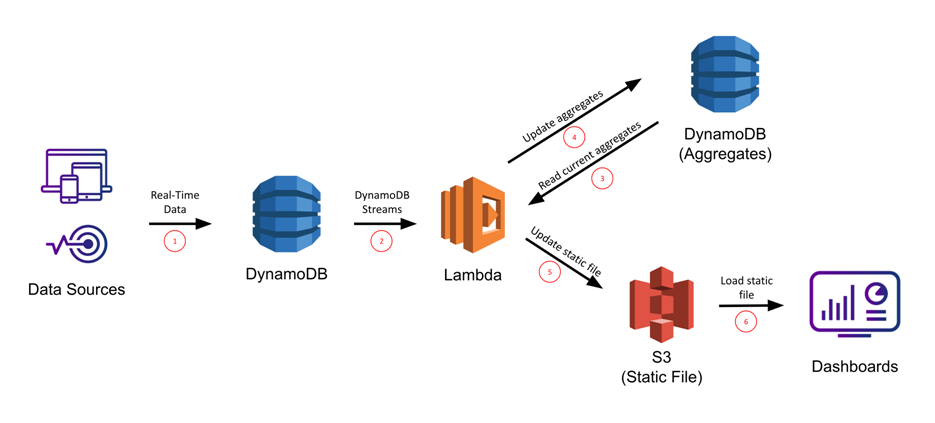
For migrating millions of customers' financial transaction data from the On-Premise Mainframe system to a non-relational database in AWS, Amazon DynamoDB is the most suitable database service.
Amazon DynamoDB is a fully managed NoSQL database service that provides fast and flexible performance for any scale of application. It is designed to store and retrieve any amount of data and can handle millions of requests per second with automatic scaling. It also supports key-value and document data models and is suitable for applications that require low latency and high throughput.
In this scenario, since the financial transaction data is non-relational and millions of records need to be stored and retrieved, a NoSQL database service like Amazon DynamoDB is the best choice. Additionally, DynamoDB supports fast and flexible data analytics with integrations with AWS services like Amazon EMR and AWS Glue.
Let's compare the other options:
- Amazon RDS: Amazon RDS is a managed relational database service that provides SQL-based database engines like MySQL, PostgreSQL, Oracle, and SQL Server. It is optimized for transaction processing and is suitable for relational data with complex queries and transactions. However, it may not be the best choice for non-relational data like financial transaction data.
- Amazon RedShift: Amazon RedShift is a fully managed data warehouse service that is optimized for OLAP (Online Analytical Processing) workloads. It is designed for analytics queries on large datasets and is not suitable for transactional workloads. Therefore, it may not be the best choice for storing millions of transactional data.
- Amazon ElastiCache: Amazon ElastiCache is a managed in-memory data store service that supports popular open-source in-memory engines like Redis and Memcached. It is designed for high-performance, low-latency use cases like caching and session management. While it can be used to store transactional data, it may not be the most suitable option for storing millions of transactional data.
Therefore, in summary, Amazon DynamoDB is the most suitable database service for migrating millions of customers' financial transaction data from the On-Premise Mainframe system to a non-relational database in AWS, providing good performance for data retrieval and data analytics.
