Data Preprocessing for Forecasting Model
Question
You work for an energy company that buys and sells energy to customers.
To get the best prices for their energy customers, your company trades financial energy derivative futures contracts.
The trading of these future contracts requires accurate forecasting of energy prices.
You need to build a model that compares spot prices (current commodity price) to future commodity prices (the price that a commodity can be bought or sold in the future)
Your model needs to assist your company's futures traders in hedging against future energy price changes based on current price predictions.
To source the model with appropriate data, you need to gather and process the energy price data automatically. The data pipeline requires two sources of data: Historic energy spot prices Energy consumption and production rates Based on the company analysts' requirements, you have decided you need multiple years of historical data.
You also realize you'll need to update the data feed daily as the market prices change.
You can gather the required data through APIs from data provider vendor systems.
Your company's traders require a forecast from your model multiple times per day to help them form their trading strategy.
So your pipeline needs to call the data provider APIs multiple times per day.
Your data-ingestion pipeline needs to take the data from the API calls, perform preprocessing, and then store the data in an S3 data lake from which your forecasting model will access the data. Your data-ingestion pipeline has three main steps: Data ingestion Data storage Inference generation Assuming you have written a lambda function that interacts with the data provider APIs and stores the data in CSV format, which of the following python libraries are the best option to perform the data preprocessing to transform the data by changing raw feature vectors into a format best suited for a SageMaker batch transform job to generate your forecast?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Answer: C.
Option A is incorrect because matplotlib and plotly are data visualization python libraries that contain no data transformation functions (see https://matplotlib.org and https://plot.ly/python/).
Option B is incorrect because boto3 is a python library used to interface with AWS services such as S3, DynamoDB, SQS, etc.
Boto3 has no data transformation functions (see https://aws.amazon.com/sdk-for-python/)
Moto is a python library used to mock interfaces to AWS services such as S3, DynamoDB, SQS, etc.
The moto library also contains no data transformation functions (see https://pypi.org/project/moto/).
Option C is correct because pandas are the best choice for data wrangling and manipulation of tabular data such as CSV formatted data (see https://pypi.org/project/pandas/)
Scikit-learn is the best python package to transform raw feature vectors into a format suited to downstream estimators (see https://scikit-learn.org/stable/modules/preprocessing.html).
Option D is incorrect because Natural Language Toolkit (NLTK) is best suited to text tagging, classification, and tokenizing, not manipulating tabular data (see https://www.nltk.org)
Scrapy is best suited to crawling functionality used to gather structured data from websites, not manipulating tabular data (see https://scrapy.org).
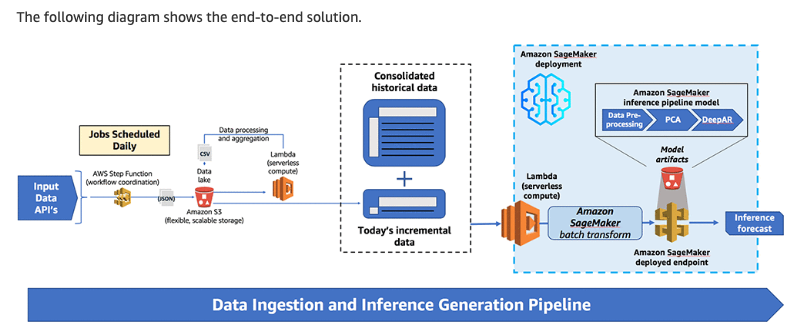
Diagram:
Here is a screenshot from the AWS Machine Learning blog depicting the solution:
Reference:
Please see the scikit-learn preprocessing data documentation: https://scikit-learn.org/stable/modules/preprocessing.html, and a detailed pandas example: https://towardsdatascience.com/why-and-how-to-use-pandas-with-large-data-9594dda2ea4c.
For the given scenario, the best option to perform data preprocessing and transform raw feature vectors into a format suitable for a SageMaker batch transform job is the combination of pandas and scikit-learn.
Here is the explanation:
Matplotlib and Plotly: These are data visualization libraries and are not suitable for data preprocessing. They are used to create visualizations such as graphs, charts, and plots from the processed data.
Boto3 and Moto: These are AWS SDKs and are used for interacting with AWS services. Boto3 is a Python library used to interact with AWS services such as S3, EC2, etc. Moto is a library used for unit testing of Boto3-based code. They are not used for data preprocessing.
Pandas and Scikit-learn: Pandas is a popular data manipulation library that provides data structures and functions to manipulate numerical tables and time-series data. It provides a set of functions for data cleaning, data wrangling, and data manipulation. Scikit-learn is a popular machine learning library that provides a set of functions for data preprocessing, feature selection, and feature extraction. It also provides a set of machine learning algorithms for regression, classification, and clustering.
Therefore, Pandas and Scikit-learn are the best option to perform data preprocessing and transform raw feature vectors into a format suitable for a SageMaker batch transform job. Pandas can be used to clean and transform the data, while Scikit-learn can be used to preprocess the data for the machine learning model.