Constructing an ETL Pipeline for Building a Data Lake from Relational Databases
Question
You work as a machine learning specialist for a book publishing company.
Your company has several publishing data stores housed in relational databases across its infrastructure.
Your company recently purchased another publishing company and is in the process of merging the two company's systems infrastructure.
A part of this merger activity is joining the two publisher book databases.
Your team has been given the assignment to build a data lake sourced from the two company's relational data stores. How would you construct an ETL pipeline to achieve this goal? (Select FOUR)
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D. E. F.Answers: B, C, E, F.
Option A is incorrect.
AWS DataSync is used to ingest data from a Network File System (NFS), not relational databases.
Option B is correct.
Once your data has been ingested from your databases, you need to catalog the data using an AWS Glue crawler.
Option C is correct.
The AWS Glue crawler can be started by a lambda function that is triggered by an S3 object create event.
Option D is incorrect.
There is no SageMaker trigger service.
Option E is correct.
You can have your AWS Glue ETL job started by a lambda function that is triggered by a CloudWatch event trigger.
Option F is correct.
You can use the AWS Database Migration Service to ingest your data from your relational databases and then store the data in an S3 bucket.
Reference:
Please see the AWS Big Data blog titled Build and automate a serverless data lake using an AWS Glue trigger for the Data Catalog and ETL jobs, and the AWS article titled How can I automatically start an AWS Glue job when a crawler run completes?
Here is a diagram representing the proposed solution:
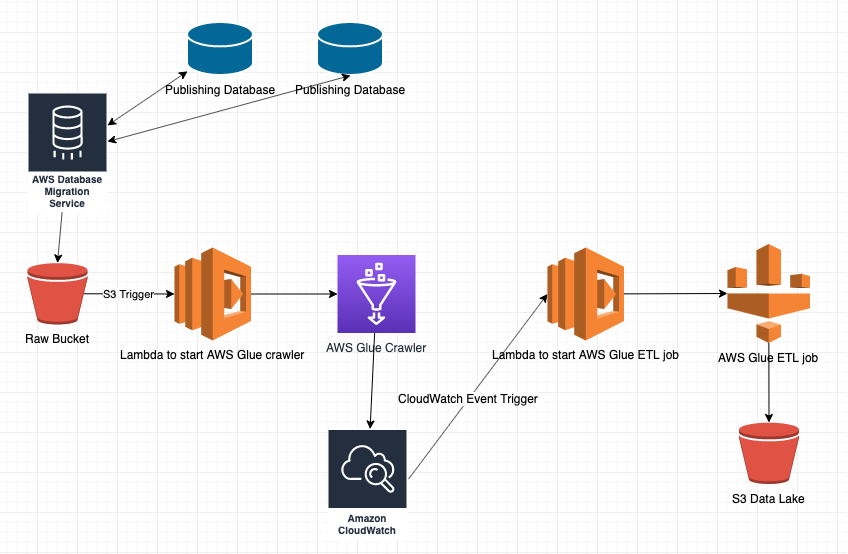
To construct an ETL (Extract, Transform, Load) pipeline to create a data lake from two publishing companies' relational databases, the following steps need to be followed:
A. Use AWS DataSync to ingest the relational data from your book data stores and store it in S3.
AWS DataSync is a managed data transfer service that simplifies and accelerates the process of transferring data between on-premises storage and AWS services. Using AWS DataSync, you can easily transfer large amounts of data from your existing data stores to S3, which is a cost-effective and scalable storage solution. AWS DataSync can be used to replicate data from your book data stores to S3.
B. Use an AWS Glue crawler to build your AWS Glue catalog.
AWS Glue is a fully managed ETL service that makes it easy to move data between data stores. AWS Glue automatically discovers and catalogs data from various sources, including S3, RDS, and other databases. An AWS Glue crawler can be used to scan the data in your S3 bucket and automatically generate the metadata for the data. This metadata can be used to create an AWS Glue catalog that contains information about the data, including the schema, format, and location.
C. Have a lambda function triggered by an S3 trigger to start your AWS Glue crawler.
To trigger the AWS Glue crawler, you can create an S3 trigger that invokes a Lambda function. The Lambda function can then start the AWS Glue crawler to scan the data in the S3 bucket and update the AWS Glue catalog with the latest metadata.
D. Use an AWS SageMaker trigger to start your AWS Glue ETL job that processes/transforms your data and places it into your S3 data lake.
AWS SageMaker is a fully managed machine learning service that makes it easy to build, train, and deploy machine learning models at scale. Using an AWS SageMaker trigger, you can start an AWS Glue ETL job that processes and transforms your data. The transformed data can then be stored in your S3 data lake.
E. Use a lambda function triggered by a CloudWatch event trigger to start your AWS Glue ETL job that processes/transforms your data and places it into your S3 data lake.
CloudWatch is a monitoring and management service provided by AWS. Using a CloudWatch event trigger, you can start a Lambda function that starts the AWS Glue ETL job to process and transform your data. The transformed data can then be stored in your S3 data lake.
F. Use AWS Database Migration Service to ingest the relational data from your book data stores and store it in S3.
AWS Database Migration Service is a fully managed service that helps you migrate databases to AWS quickly and securely. Using AWS Database Migration Service, you can replicate data from your book data stores to S3. The replicated data can then be processed and transformed using AWS Glue ETL jobs and stored in your S3 data lake.
In summary, to construct an ETL pipeline to create a data lake from two publishing companies' relational databases, you can use AWS DataSync to ingest data from your book data stores to S3, use AWS Glue to build a catalog of metadata for your data, use Lambda functions or SageMaker triggers to start AWS Glue ETL jobs to process and transform your data, and store the transformed data in your S3 data lake. You can also use AWS Database Migration Service to replicate data from your book data stores to S3.
