Building a Scalable Data Pipeline for Real-time Gaming App Analysis
Question
You work for a software company that has developed a popular mobile gaming app that has a large, active user base.
You want to run a predictive model on real-time data generated by the app users to see how to structure an upcoming marketing campaign.
The data you need for the model is the user's age, location, and level of activity in the game as measured by playing time.
You need to filter the data for users who have not yet signed up for your company's premium service.
You'll also need to deliver your data in json format, convert the playing time into a string format, and finally put the data onto an S3 bucket. Which of the following is the simplest, most cost-effective, performant, and scalable way to architect this data pipeline?
Answers
Explanations
Click on the arrows to vote for the correct answer
A. B. C. D.Answer: B.
Option A is incorrect.
This option has a bottleneck at the single EC2 instance used to gather the log data from the application log files.
This solution would not be the most scalable.
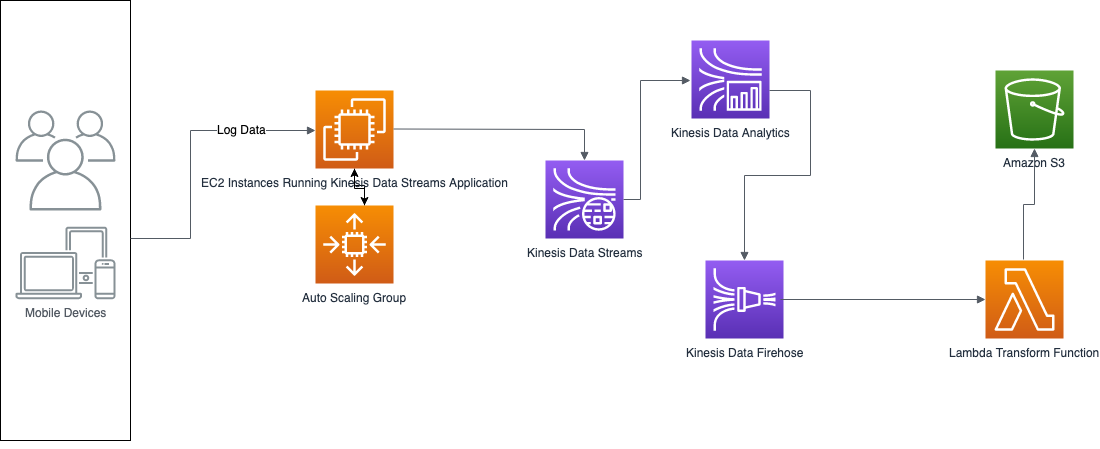
Option B is correct.
This option scales well at the Kinesis Data Streams application level because of the Auto Scaling Group.
It also uses Kinesis Data Analytics to transform the data into the subset you need.
It uses the Kinesis Firehose lambda option to convert the playing time to the proper format.
Option C is incorrect.
This option does not transform the log data gathered by the Kinesis Firehose before writing the data to the S3 bucket.
Option D is incorrect.
This option does not transform the log data gathered by the Kinesis Data Streams application before writing the data to the S3 bucket.
Reference:
Please see the AWS developer guide documentation titled What is Kinesis Data Streams, the AWS Auto Scaling documentation, the Amazon Kinesis Data Firehose documentation, and the Amazon Kinesis Data Analytics documentation.
Here is a diagram of the solution:
The most cost-effective, performant, and scalable way to architect this data pipeline is option C - Create a Kinesis Firehose which gathers the data and puts it onto your S3 bucket.
Here's why:
Data Collection: Kinesis Firehose can be configured to capture data directly from mobile devices via its API or from streaming sources like Kinesis Data Streams, which can be used to collect log data generated by the mobile app. In this scenario, Kinesis Data Streams is not required because the data is not being transformed, just filtered. Therefore, we can avoid the additional overhead and complexity of using Kinesis Data Streams.
Data Transformation: The data needs to be filtered based on the criteria provided in the question. Kinesis Analytics is not necessary in this case as filtering can be done directly in Kinesis Firehose by configuring a transformation Lambda function. Additionally, the playing time can be converted to a string format using a Lambda function in Kinesis Firehose. So, the transformation can be achieved in a simple and cost-effective way using just Kinesis Firehose.
Data Delivery: The data needs to be delivered in JSON format and stored in an S3 bucket. Kinesis Firehose provides an option to deliver data directly to an S3 bucket in a compressed and optimized format, which is highly scalable and cost-effective.
Scalability: Kinesis Firehose is highly scalable and can handle large volumes of data without requiring any manual intervention. It automatically scales based on the incoming data rate and can handle bursts of data seamlessly.
Cost: Kinesis Firehose is a pay-as-you-go service, which means that you only pay for the data that is delivered to your S3 bucket. Additionally, there are no upfront costs or minimum fees, making it a cost-effective option.
Overall, option C - Create a Kinesis Firehose which gathers the data and puts it onto your S3 bucket - is the simplest, most cost-effective, performant, and scalable way to architect this data pipeline.