Question 78 of 170 from exam DP-200: Implementing an Azure Data Solution
Question
HOTSPOT -
A company plans to use Platform-as-a-Service (PaaS) to create the new data pipeline process. The process must meet the following requirements:
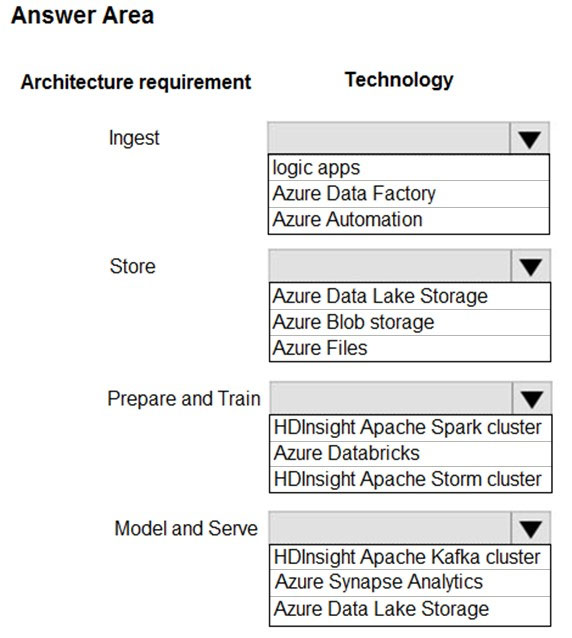
Ingest:
-> Access multiple data sources.
-> Provide the ability to orchestrate workflow.
-> Provide the capability to run SQL Server Integration Services packages.
Store:
-> Optimize storage for big data workloads
-> Provide encryption of data at rest.
-> Operate with no size limits.
Prepare and Train:
-> Provide a fully-managed and interactive workspace for exploration and visualization.
-> Provide the ability to program in R, SQL, Python, Scala, and Java.
-> Provide seamless user authentication with Azure Active Directory.
Model & Serve:
-> Implement native columnar storage.
-> Support for the SQL language.
-> Provide support for structured streaming.
You need to build the data integration pipeline.
Which technologies should you use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
Hot Area:
Explanations
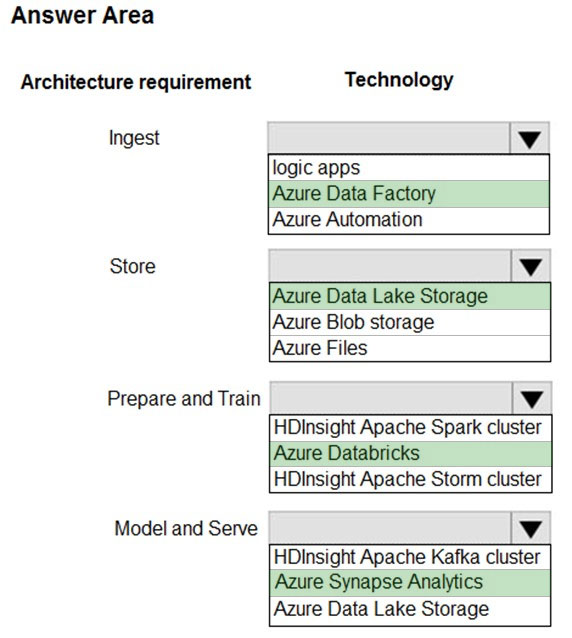
Ingest: Azure Data Factory -
Azure Data Factory pipelines can execute SSIS packages.
In Azure, the following services and tools will meet the core requirements for pipeline orchestration, control flow, and data movement: Azure Data Factory, Oozie on HDInsight, and SQL Server Integration Services (SSIS).
Store: Data Lake Storage -
Data Lake Storage Gen1 provides unlimited storage.
Note: Data at rest includes information that resides in persistent storage on physical media, in any digital format. Microsoft Azure offers a variety of data storage solutions to meet different needs, including file, disk, blob, and table storage. Microsoft also provides encryption to protect Azure SQL Database, Azure Cosmos
DB, and Azure Data Lake.
Prepare and Train: Azure Databricks
Azure Databricks provides enterprise-grade Azure security, including Azure Active Directory integration.
With Azure Databricks, you can set up your Apache Spark environment in minutes, autoscale and collaborate on shared projects in an interactive workspace.
Azure Databricks supports Python, Scala, R, Java and SQL, as well as data science frameworks and libraries including TensorFlow, PyTorch and scikit-learn.
Model and Serve: Azure Synapse Analytics
Azure Synapse Analytics/ SQL Data Warehouse stores data into relational tables with columnar storage.
Azure SQL Data Warehouse connector now offers efficient and scalable structured streaming write support for SQL Data Warehouse. Access SQL Data
Warehouse from Azure Databricks using the SQL Data Warehouse connector.
Note: Note: As of November 2019, Azure SQL Data Warehouse is now Azure Synapse Analytics.
https://docs.microsoft.com/bs-latn-ba/azure/architecture/data-guide/technology-choices/pipeline-orchestration-data-movement https://docs.microsoft.com/en-us/azure/azure-databricks/what-is-azure-databricks